Pues después de mucho tiempo vuelvo a centreon. He probado zabbix, grafana, etc. todos muy guays pero a la hora de configurarlos simplemente me pierdo, así que vuelvo a lo ya conocido y aprovecho para refrescar conocimientos.
Hago un manual porque me puse a instalarlo a saco y luego el poller no arrancaba no sé muy bien porqué, así que hice lo que un jefe sabiamente me recomendó al instalar una impresora y al ver que sobraban piezas que debía leer el manual. Así que aprovecho para hacer la versión en castellano.
Lo primero de todo será descargar la iso de centreon 20.04. También hay la opción de descargarse una máquina ya preparada para virtualbox y vmware. Como voy a instalarlo en un qemu uso la iso. También existe la opción de instalarlo como paquete (sobre centos) o usando los ficheros source.
Así que proseguimos con la instalación con la iso.
De mientras vamos creando la máquina qemu con los requisitos necesarios. En mi caso le pongo 6Gb de RAM y 60Gb de disco duro.
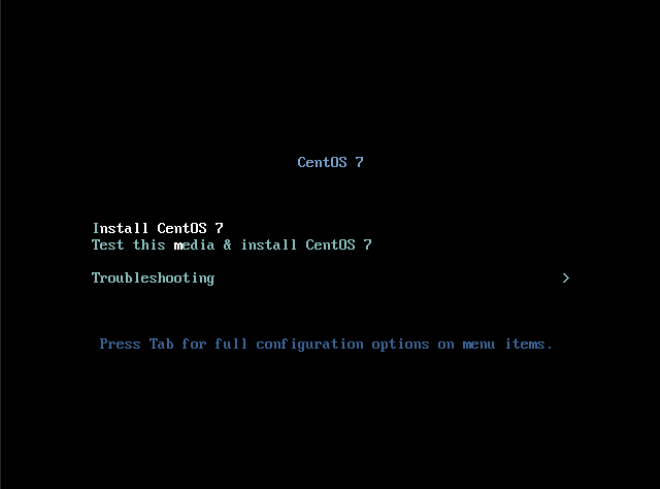
Una vez descargada la iso arrancamos la máquina virtual e iniciamos la instalación y le indicamos “Install CentOS 7”:
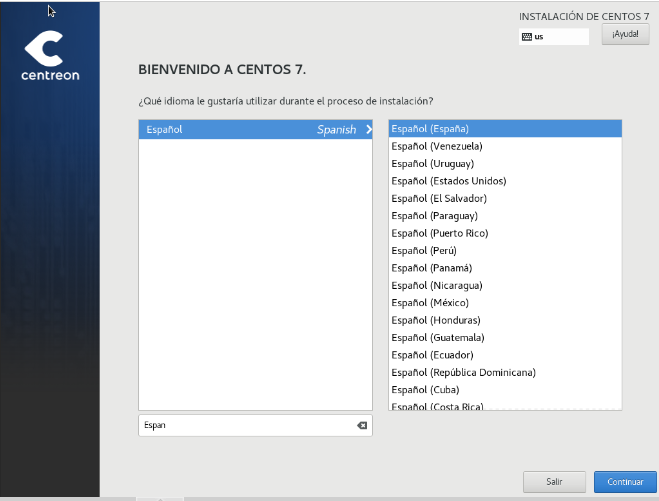
Seleccionamos el idioma de la instalación:
Y nos aparece la siguiente pantalla en la que tendremos que configurar varias cosas:
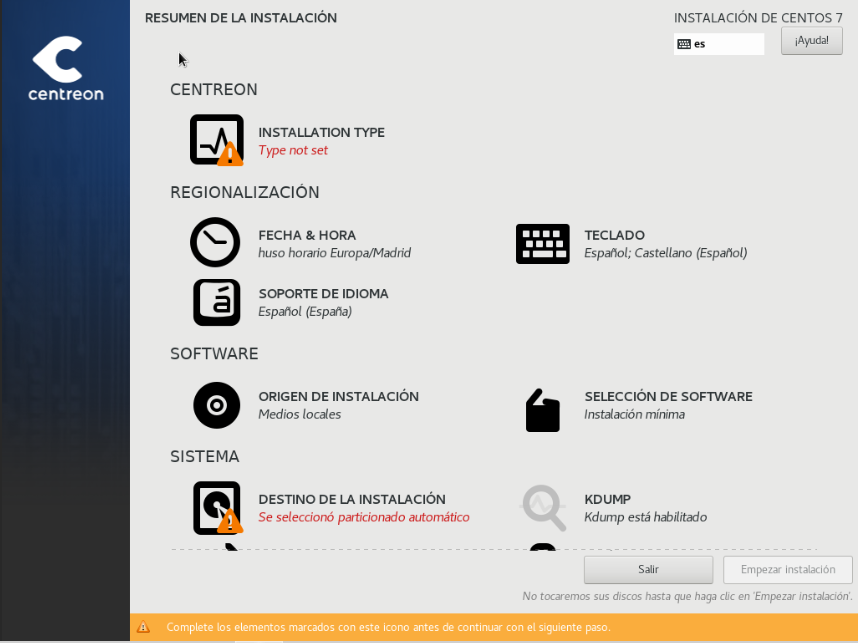
La primera será indicar el tipo de instalación:
Central with database: Instala Centreon (la interfaz web y la base de datos), el motor de monitoreo y el Broker.
Central without database: Instala …